|
Photoshop CS6 (32-bit) is one of the few major Windows programs that appear to work pretty well under WINE. I've tested it under both Wine 2.2 and 3.0 rc.
You will probably need to use winetricks to install atmlib, to prevent crashes associated with the text tool. Other than that, resist the temptation to install random overrides.
0 Comments
Out of curiousity, I tried Office 2013 on Linux Wine 2.0, given that it is now "possible". In general, I decided not to continue using it, because it still has some bugs when running on my favorite Arc-dark theme, but it looks quite usable. I was half hoping that Skype for Business was working, but no such luck! Everything else looks okay though. Here's the steps I took to install it on XUbuntu 17.10: Follow this guide to install either Linux stable or linux staging. Both worked fine, I am not sure I noticed any difference between the two. Obtain a copy of Office 2013, 32-bit. 64-bit is known to have problems, so not worth wasting your time with it. Install winbind and winetricks Code Editor
Start winbind: Code Editor
Set your WIN32 prefix in /etc/environment, log out and log in. Alternately you can set it for a particular shell, or prefix each command with setting the variable. I prefer the /etc/environment approach: Okay, you are back in, set up wine (this assumes you are starting with a brand new installation): Wait for the installation of MXML6 and corefonts to install, then set it back to win7 just in case it changed: now start installing your office package. I used the exe from the Microsoft HUP program, but I imagine the SETUP.EXE from a CD should also work: ....and let it complete. When done (or really, at the same time), fire up regedit Code Editor
And add a key HKEY_CURRENT_USER\Software\Wine, called "Direct3D". Then create a DWORD value MaxVersionGL inside this key, and set it to hexadecimal 0x30002. If you omit this step, you may end up with a black app screen on launch.
A few more hints for a succesful installation:
That is about it, hopefully your installation will complete and you will be able to launch Word, Excel, Outlook, and OneNote should also work. Consider using it with a light theme. Group policy is one of those things that you live with, and unless you are an administrator, don't pay much attention to, until someone asks you to write a group policy extension. Most group policies are simple registry changes. However, some more complex tasks call for the creation of a group policy extension, which is basically a DLL which gets invoked by the group policy infrastructure when a targeted group policy arrives. We use such an approach to change a group policy data to a different subsystem's format (XML), when a new group policy arrives. Group policy extensions are documented in the microsoft documentation. Poorly, I might add. The sample they provide is the following: Processing a changed GPO
But really, the devil here is in the details.. What do you do with the policy object inside the loop? The policy change data is not in the object you receive, and really nowhere obvious in sight.
What we know Okay, so let's figure out what we know. To create group policy extension, we need to create DLL, with a method implementing either ProcessGroupPolicy or ProcessGroupPolicyEx callbacks. We then need to create registration and unregistration functions (although, that may not be specifically required, if you can register through other means). These registration functions will register our extension in the registry, and advertise the entry point. So far so good. And the missing part Once implemented per microsoft specifications, you will start receiving GPO delete and change messages. To process these, here's what you need to know:
So the flow to handle a GPO change (or deletion, for that matter):
Hope this helps. By the way, if you are writing this in C++, ensure you export your callback method as plain C. Also, due to the callback calling convention, this will probably not work in managed code. I am not a big fan of C++, although it's paid my bills for a few years. These days when I cannot use a more modern language, I tend to reach for plain C more often than not. I find its simplicity much more elegant and pleasant. One of the tasks I had to accomplish at one point was interfacing with Windows WMI, which is basically a COM interface. This task is not that difficult, even in plain C. The approach is fairly similar, with a little syntactic difference. Consider for example the code to get a WBEM Locator object in C++: This code in C becomes: Code Editor
All we've really done here is referecing through the lpVtbl struct member, and providing the object itself as the first parameter to the call. This pattern repeats itself throughout the code when replacing C++ with plain C. You can then adapt most C++ WMI sample code to C. So let's see how we'd query WMI in C. . Note that I leave out the error handling for brevity sake, but wherever you see {...} you should take care to free allocated strings and release objects. Querying WMI in plain C
In writing code such as this that uses a lot of allocations and deallocations, I usually find it easier to allocate at point of use, and deallocate immediately, instead of allocating at the top of function and deallocating at the bottom. But your preference may vary. Also note that although this code uses tchars for compatibility reasons, the WMI strings are always wide strings. To invoke methods, it is fairly similar. Following the above pattern, we enumerate instances. Calling methods on WMI instance providers
So that got us a reference to an instance, now we call it. I find it useful to wrap every method invocation in its own C method. Calling a method on an instance
So that's about it. You really can pick up any C++ function and convert them to C easily. About the only other complication may be that you have to use SysAllocString/SysFreeString instead of the _bstr_t type when creating your BSTRs (since _bstr_t is a class).
Akka actors can get overwhelmed, poor things. Their mailbox can only hold so many messages (either because of preconfigured bounds or memory constraints), and unpleasant things can happen when it overflows. Furthermore, uncontrolled growth of mailboxes can have bring up a whole different set of issues. Although this post focuses on the work-pulling pattern, I am going to start with an overview of Akka actors and associated constructs. If you do not want to sit through this discussion, skip down to the section titled Work-Pulling Pattern. So let us review a few basics. Consider an actor system of two actors, as shown in this diagram, where Actor A has some data it wants to tell Actor B. 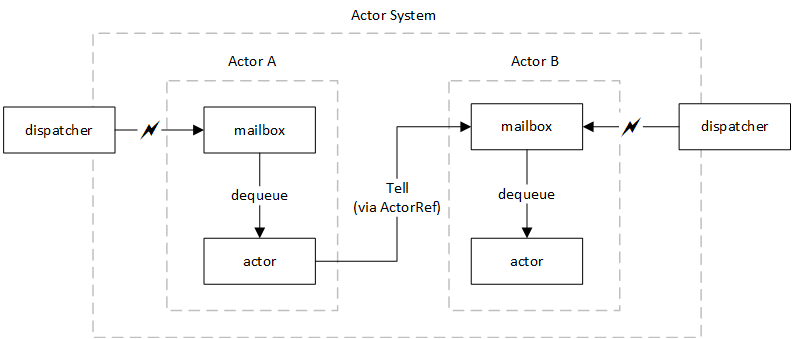 The interesting concepts here are the Actor System, the dispatchers, and the actors with their mailboxes. Let's review each one: Actor Systems A useful system contains at least two actors; arthouse performance artists specializing in monologues need not apply. These actors run inside a bounded construct called an Actor System. This construct provides (among other things) a default dispatcher and a default mailbox type to its actors. In some applications, actor systems can be used as failure zones as seen in the bulkhead pattern. Actors An actor is a "fundamental unit of computation that embodies processing, storage, and communication" (per Carl Hewitt, 1973). This means that we are often not concerned with how actors are implemented, we treat them almost as primitives. Instead, we turn our attention to defining their behavior and designing systems of actors. Each actor is composed of a mailbox which contains incoming messages, and the actor business logic which encapsulates the user-defined behavior and state. A dispatcher is responsible for moving messages into the actor's queue, and also dequeuing messages for consumption by the aforementioned business logic. Fundamentally important, this dispatcher ensures that the only one message is dequeued and enters processing at any given time. Dispatchers Dispatchers are rule engines that control enqueing and dequeing messages to and from an actors’s mailbox. Each actor can have its own dispatcher, but unless specifically called for, it inherits the dispatcher of the current Actor System. I struggle if to draw the dispatcher as part of the actor, or an outside rule acting on the actor. There are three types of dispatchers currently defined. In general, what you are looking for is the proper threading strategy for handling your actor's mailbox.
For more information, see the relevant page in the Akka documentation, which discusses additional tidbits, including ways to define the dispatcher for your actors through configuration. MailboxesActors process messages serially, by definition. This means some sort of a data structure must exist to hold the incoming messages while they await processing. This is the actor’s mailbox (normally one per actor, unless the BalancingDispatcher is used). The currently defined mailboxes are:
To choose a mailbox for your actor, you should extend your actor and implement RequiresMessageQueue[T] with T mapping to a configured type. For more information and code, see Mailboxes in the Akka documentation. Work-Pulling Pattern An indicator of a good system design is predictability. Although blocking is generally undesirable, neither are the effects of unpredictable queue growth. To address this, we turn the paradigm on its head and have destination actors pull messages rather than wait for them to be pushed. Side note: reactive streams uses backpressure to address this issue. If you can adopt akka-streams, this work-pulling discussion is mostly academic. The work-pulling pattern looks something like this: 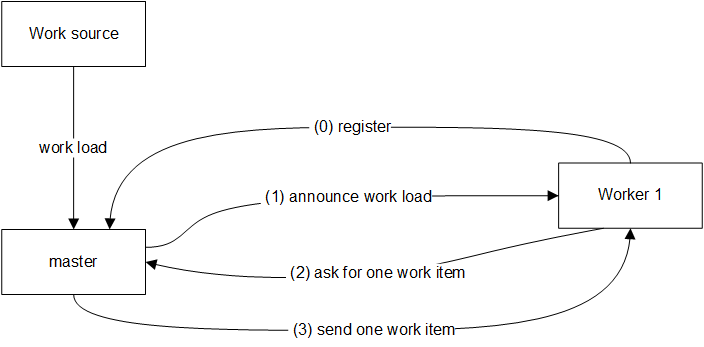
So what may the code look like? Here's a naive master and worker. I call it naive because there is no specific effort to optimize he collections used, or the broadcasting from the master to worker. Code Editor
To demo this process, we may try something like: Code Editor
Which gives us the following output: Code Editor
And that's about it. The code can definitely be optimized in various ways, it is only meant to show the basic concept. Various things to consider are the collections being used, whether workers can come in and participate after a workload has been advertised, and other application-specific concerns. Structuring the worker actors as children of the master actor, where appropriate, may also reduce the need to maintain a discrete list of workers, or the need for the worker-advertisement (WorkerIsAvailable) event.
Ok, so SOAP is not exactly sexy, nor is it pleasant to work it. And scala doesn't have any 'native' frameworks for SOAP services (that I know of). But, we can still leverage JAX-WS. First, let's write our service class. We will create a service that has an action called "hashing", a method called "test", which takes a string parameter "mystr" and return the SHA256 hash of that string. We'll also enable WS-Addressing for good measure. Code Editor
The above is probably self documenting, especially if you've done web services in java., so I won't spend time on it. Let's now focus on the main class. Couldn't be simpler. Let's test it.. we POST this document, with content set to application/soap+xml: Code Editor
And we get back: Code Editor
Well, yep, it seams like it worked. To route into Akka actors framework, we could do as follows: Create an actor to hold our business rule: Code Editor
And modify our test() method in the service to use the Ask pattern: Code Editor
Our response is now: Code Editor
Hope this helps. Connecting this to akka-streams is now a step away.
TL;DR If you already understand hash-linked lists and merkle trees, and how to represent transactions in a Merkle tree, here’s what's discussed in the remainder of the post: A blockchain is simply a hash-linked list of blocks, where each block contains the Merkle root of a tree encoding one or more transactions. Visually, it may look as follows: 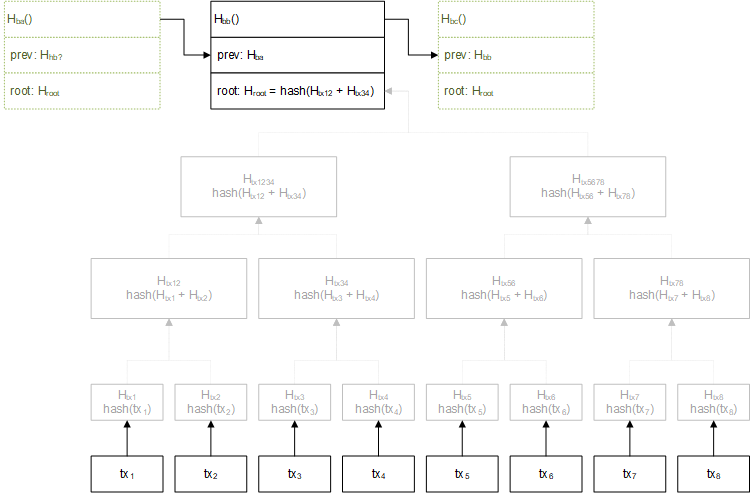 Each block has a prev field containing the hash value of the previous block (unless it’s the first block in the chain). A root field contains the Merkle root of a tree that encodes the transactions associated with the block. The Merkle tree itself is not part of the blockchain, but it is calculated at run-time to validate the consistency of a given block. The hash functions used in blockchain are usually SHA-256. Note: prev and root may not match the names of the fields in an actual implementation. And for a few details... Hash-linked lists are sometimes referred to as hash chains, but this is a bit confusing, since hash chains are often represented as Merkle trees, so I will avoid that naming convention. In this post I will refer to them as hash-linked lists, until I figure out the proper name for this data structure. The Hash-Linked List A hash-linked list is similar to a normal single-linked list, where instead of pointers, we use the hash of the previous item in the list. This allows the validation of a linked item, by recalculating its hash as needed. Consider the example from the previous diagram:  The above list contains three items, ba, bb, and bc. The head item is often called the genesis block in Bitcoin terminology, and the tail is called.. the tail, I think. Suppose we must add an item bd to the list. Given a hash function H(), we must:
The Merkle Tree The Merkle tree was originally proposed by Ralph Merkle in 1979. This data structure is a tree of hashes, widely used in cryptography, and many peer to peer systems. In Bitcoin specifically, the leaves of the Merkle tree are Bitcoin transactions, and the topmost hash (the Merkle root) is stored as part of each block data. A Merkle tree looks similar to the following, with tx(n) being a Bitcoin transaction or some other type of data. 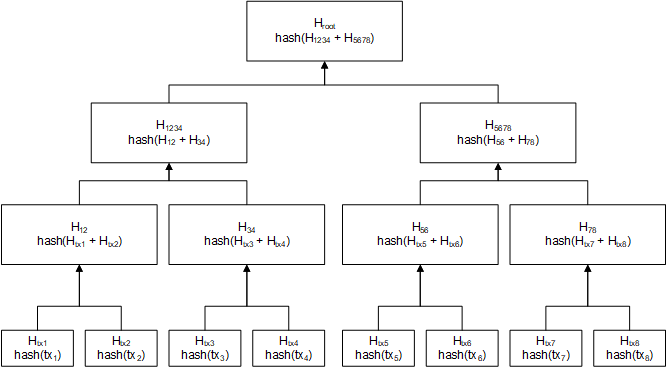 To read this tree correctly, start from the bottom, and assume we have eighttransactions (tx(1), tx(2), tx(3), tx(4), and so on) that we want to encode,
If you paid attention, you noticed that this is a binary tree. A Merkle tree is not necessarily a binary tree, but enforcing a binary structure helps minimize the number of hashes needed to reconstruct a given branch. Furthermore, due to its binary nature, it expects an even number of transactions (or data being represented). By convention in Bitcoin, to represent a block with an odd number of transactions, the last item in the block is paired with itself. References: Bitcoin Developer Reference, https://bitcoin.org/en/developer-reference Antonopoulos, A. M. (2017). Mastering bitcoin: programming the open blockchain. Bejing: OReilly. |
ArchivesCategories
All
|
 RSS Feed
RSS Feed
